A frequent assumption that people make about SQL is that a query will return rows in the same order every time. For example, if you run the following query in the AdventureWorks database:
SELECT * FROM Production.Product
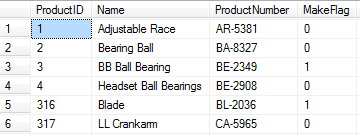
You will see that all rows returned appear to be in order of ProductID, as this has used the clustered index to return the data. However, nothing in the query has specified that you want the rows ordered by name. Try this query:
SELECT ProductID, Name FROM Production.Product
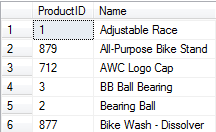
This query returns the ProductID and the Name, but ordered by the Name. This is because the index used was AK_Product_Name, which is on the [Name] column. This index satisfies the query by being the smallest index that can service the query. As each row in the index is smaller than in the clustered index, more rows can be squeezed into each page.
However, what happens if someone adds a new index onto the table, and the query is run again?
CREATE NONCLUSTERED INDEX ncix_ProductID_Name ON
Production.Product(ProductID, Name) GO SELECT ProductID, Name FROM Production.Product
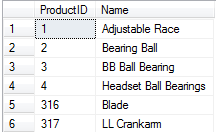
Suddenly, the results are being returned ordered by ProductID. SQL Server now has two choices of index to use to service this query, and both are the same cost. There is no guarantee which index will be used. Turn on the execution plan for the previous query (Query | Include Actual Execution Plan, or Control-M in Management Studio), and run the query again to see the plan.

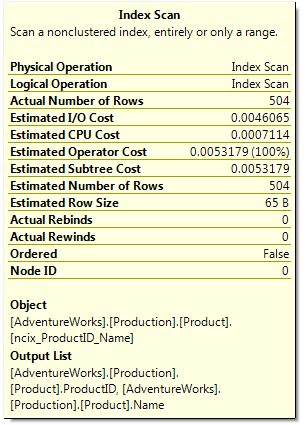
Note that the Ordered property is False. This means that whatever order has been returned does not mean that the result set is sorted. It might be in a specific order, but this is not guaranteed. As you can see in the results above, while the index used was the AK_ProductID_Name one we just created, the results weren’t returned in order of ProductID. When a Index Scan occurs in this situation, SQL Server grabs every page of the index in the quickest manner possible, and processes the rows. It is possible that the index is fragmented, and pages are not stored in order on the disk. Consider a page split. If a row is inserted into this table (with Identity Insert on) in the middle, and there is no room for the row, a page split will occur. If there is no free pages in the extent, a new extent will be allocated, and this could be on a completely different part of the file. When all pages are read in, the split page may be processed last due to its location in the MDF file.
On the other hand, if an ORDER BY clause is used in the query, the Ordered property will be true, and SQL Server will “walk” the pages of the index in the proper order to get the sorted version of the results.
SELECT ProductID, Name FROM Production.Product ORDER BY ProductID
![]()

If there is no index that will return the data in the proper order, then SQL Server will choose the most efficient index, and then sort the data:
SELECT ProductID, Name, ProductNumber FROM Production.Product ORDER BY ProductNumber

Note that sorting a result set can be quite expensive for the server, as TempDB must be used, which will involve writing to the TempDB transaction log. If the application is a desktop app it may be worth getting the client to perform the sort, rather than the database.
Note that if you try to run these queries as I’ve done in this post, you may get different results. Some things may appear to be ordered in different ways to how I’ve described it, but that’s really the whole point – if you want something ordered, include an ORDER BY clause.